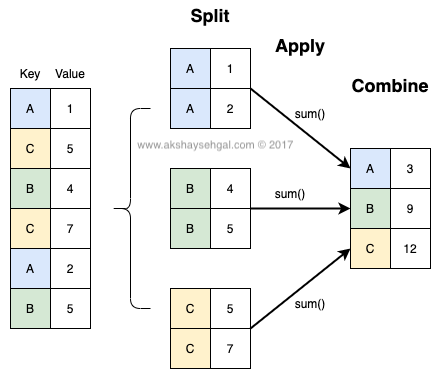
Before we can start writing code, let's explore the basics behind a groupby operation. The core concept behind any groupby operation is a three step process called Split-Apply-Combine.
- Split: Splitting the data into groups based on some criteria
- Apply: Applying a function to each group independently
- Combine: Combining the results into a data structure
Here is a diagram to make this more intuitive.